Unidad 4
Memoria
Compartida Distribuida
Los sistemas de Memoria Compartida Distribuida (MCD) son sistemas que,
mediante software, emulan semántica de memoria compartida sobre hardware que
ofrece soporte solo para comunicación mediante paso de mensajes. Este modelo
permite utilizar una red de estaciones de trabajo de bajo costo como una
maquina paralela con grandes capacidades de procesamiento y amplia
escalabilidad, siendo a la vez fácil de programar. El objetivo principal de
estos sistemas es permitir que un multicomputador pueda ejecutar programas
escritos para un multiprocesador con memoria compartida.
Cada uno
de los nodos en un sistema de MCD aporta una parte de su memoria local para
construir un espacio global de direcciones virtuales que será empleado por los
procesos paralelos que se ejecuten en el sistema. El software de MCD se encarga
de interceptar las referencias a memoria que hacen los procesos, y
satisfacerlas, ya sea local o remotamente. Si los accesos a memoria hacen
referencia a posiciones almacenadas remotamente, es necesario llevar a cabo una
transferencia a través de la red, con el consecuente overhead que esto
conlleva. Por esta razón los sistemas de MCD tienen un comportamiento no
uniforme respecto a los accesos a memoria. Sin embargo, a diferencia de los
sistemas NUMA, en este caso los procesadores no tienen acceso a memoria remota
en forma directa. Es necesario que medie un componente de software para
permitir los accesos que no son locales.

4.1 Configuraciones Memoria Compartida Distribuida
Computación Paralela
·
Es un
conjunto de procesadores capaces de cooperar en la solución de un problema.
· El
problema se divide en partes. Cada parte se compone de un conjunto de
instrucciones. Las instrucciones de cada parte se ejecutan simultáneamente en
diferentes CPU.
Técnicas
computacionales que descomponen un problema en sus tareas y pistas que pueden
ser computadas en diferentes máquinas o elementos de proceso al mismo tiempo.

¿Por qué utilizar computación
paralela?
* Reducir el tiempo de procesamiento
- * Resolver problemas de gran envergadura.
-
* Proveer concurrencia.
* Utilizar recursos remotos de cómputo cuando los
locales son escasos.
* Reducción de costos usando múltiples recursos
"baratos" en lugar de costosas supercomputadoras.
* Ampliar los límites de memoria para resolver
problemas grandes.
El mayor problema
de la computación paralela radica en la complejidad de sincronizar unas tareas
con otras, ya sea mediante secciones críticas, semáforos o paso de mensajes,
para garantizar la exclusión mutua en las zonas del código en las que sea
necesario.
La computación
paralela está penetrando en todos los niveles de la computación, desde
computadoras masivamente paralelas usados en las ciencias de larga escala
computacional, hasta servidores múltiples procesadores que soportan
procesamiento de transacciones. Los principales problemas originados en cada
uno de las áreas básicas de la informática (por ejemplo, algoritmos, sistemas,
lenguajes, arquitecturas, etc.) se vuelven aún más complejos dentro del
contexto de computación paralela.
4.1.1 De Circuitos Basados en Bus, anillo o
con conmutador
Arquitecturas de MCD
Existen
varias formas de implantar físicamente memoria compartida distribuida, a
continuación se describen cada una de ellas.
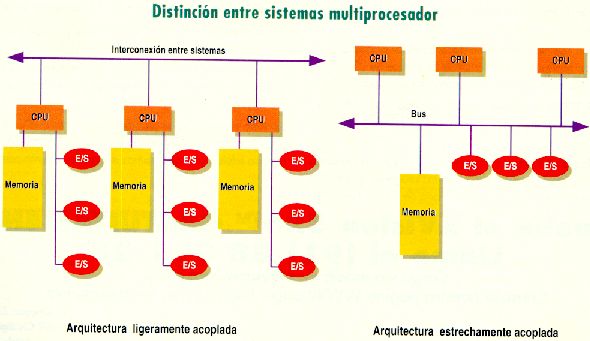
Memoria
basada en circuitos: Existe una única área de memoria y cada micro tiene
su propio bus de datos y direcciones (en caso de no tenerlo se vuelve un
esquema centralizado)
MCD basada en bus: En este esquema los micros
comparten un bus de datos y direcciones por lo que es más barato de
implementar, se necesita tener una memoria caché grande y sumamente
rápida.
MCD basada en anillos: Es más tolerante a fallos, no
hay coordinador central y se privilegia el uso de la memoria más cercana.

MCD basada en conmutador: Varios micros se conectan entre
sí en forma de bus formando un grupo, los grupos están interconectados entre sí
a través de un conmutador.
4.2 Modelos de
Consistencia
La duplicidad de los bloques compartidos aumenta el
rendimiento, pero produce un problema de consistencia entre las diferentes
copias de la página en caso de una escritura. Si con cada escritura es
necesario actualizar todas las copias, el envío de las páginas por la red
provoca que el tiempo de espera aumente demasiado, convirtiendo este método en
impracticable. Para solucionar este problema se proponen diferentes modelos de
consistencia, que establezcan un nivel aceptable de acercamiento tanto a la
consistencia como al rendimiento. Nombramos algunos modelos de consistencia,
del más fuerte al más débil: consistencia estricta, secuencial, causal, PRAM,
del procesador, débil, de liberación y de entrada.

4.2.1 Estricta Causal Secuencial Débil, de liberación y de
entrada
Consistencia Estricta
El modelo
de consistencia más restrictivo es llamado consistencia estricta y es definido
por la siguiente condición Cualquier lectura sobre un item de dato x retorna un
valor correspondiente con la más reciente escritura sobre x
a) Un
almacenamiento estrictamente consistente.
b) Un
almacenamiento que no es estrictamente consistente.
Consistencia Causal
El modelo
de consistencia causal (Hutto and Ahamad, 1990) es un debilitamiento de la
consistencia secuencial. Se hace una diferenciación entre eventos que están
potencialmente relacionados en forma causal y aquellos que no. Las operaciones
que no están causalmente relacionadas se dicen concurrentes.
La
condición a cumplir para que unos datos sean causalmente consistentes es:
Escrituras
que están potencialmente relacionadas en forma causal deben ser vistas por
todos los procesos en el mismo orden. Escrituras concurrentes pueden ser vistas
en un orden diferente sobre diferentes máquinas.
Esta
secuencia es permitida con un almacenamiento causalmente consistente, pero no
con un almacenamiento secuencialmente consistente o con un almacenamiento
consistente en forma estricta.
Consistencia secuencial
La
consistencia secuencial es una forma ligeramente más débil de la consistencia
estricta. Satisface la siguiente condición:
El
resultado de una ejecución es el mismo si las operaciones (lectura y escritura)
de todos los procesos sobre el dato fueron ejecutadas en algún orden secuencial
y las operaciones de cada proceso individual aparecen en esta operaciones de
cada proceso individual aparecen en esta secuencia en el orden especificado por
su programa
a) Un dato almacenado secuencialmente consistente.
b) Un dato almacenado que no es secuencialmente
consistente.
Consistencia Débil
Los
accesos a variables de sincronización asociadas con los datos almacenados son
secuencialmente consistentes.
Propiedades
No se
permite operación sobre una variable de sincronización hasta que todas las
escrituras previas de hayan completado. No se permiten operaciones de escritura
o lectura sobre ítems de datos hasta que no se hayan completado operaciones
previas sobre variables de sincronización.
Consistencia liberación (Release)
El modelo
de consistencia release, RC [27], se basa en el supuesto de que los accesos a
variables compartidas se protegen en secciones críticas empleando primitivas de
sincronización, como por ejemplo locks. En tal caso, todo acceso esta precedido
por una operación seguido por una operación release. Es responsabilidad del
programador que esta propiedad se cumpla en todos los programas.
Puesto que
ningún otro proceso, ni local ni remoto, puede acceder a las variables que han
sido modificadas mientras se encuentren protegidas en la sección crítica, la
actualización de cualquier modificación puede postergarse hasta el momento en
que se lleva a cabo la operación release.
La
operación release no se da por completada hasta que la actualización haya sido
propagada a todos aquellos procesadores en donde haya replicas. Con RC, la
propagación de un conjunto de modificaciones a memoria compartida se lleva a
cabo con un costo fijo.
Propagación
de Actualizaciones bajo RC y LRC de código sin proteger. En consecuencia obtuvo
un valor inconsistente para la variable leída.
4.3 Mcd
en base a Páginas
El esquema de MCD propone un espacio de direcciones de memoria virtual
que integre la memoria de todas las computadoras del sistema, y su uso mediante
paginación. Las páginas quedan restringidas a estar necesariamente en un único
ordenador. Cuando un programa intenta acceder a una posición virtual de
memoria, se comprueba si esa página se encuentra de forma local. Si no se
encuentra, se provoca un fallo de página, y el sistema operativo solicita la
página al resto de computadoras. El sistema funciona de forma análoga al
sistema de memoria virtual tradicional, pero en este caso los fallos de página
se propagan al resto de ordenadores, hasta que la petición llega al ordenador
que tiene la página virtual solicitada en su memoria local. A primera vista
este sistema parece más eficiente que el acceso a la memoria virtual en disco,
pero en la realidad ha mostrado ser un sistema demasiado lento en ciertas
aplicaciones, ya que provoca un tráfico de páginas excesivo.
Una
mejora dirigida a mejorar el rendimiento sugiere dividir el espacio de
direcciones en una zona local y privada y una zona de memoria compartida, que
se usará únicamente por procesos que necesiten compartir datos. Esta
abstracción se acerca a la idea de programación mediante la declaración
explícita de datos públicos y privados, y minimiza el envío de información, ya
que sólo se enviarán los datos que realmente vayan a compartirse.
4.3.1 Diseño Replica Granularidad Consistencia, propietario y
copias
Razones
para la Replicación Hay dos razones principales para la replicación
de datos:
Confiabilidad
Continuidad
de trabajo ante caída de la réplica Mayor cantidad de copias mejor protección
contra la corrupción de datos
Rendimiento
El
SD escala en número Escala en área geográfica (disminuye el tiempo de acceso al
dato) Consulta simultánea de los mismos datos, se refiere a la
especificidad a la que se define un nivel de detalle en una tabla.
4.4 Mcd en Base a Variables
En
los MCD basados en variables busca evitar la compartición falsa ejecutando un
programa en cada CPU que se comunica con una central, la que le provee de
variables compartidas, administrando este cualquier tipo de variable, poniendo
variables grandes en varias páginas o en la misma página muchas variables del
mismo tipo, en este protocolo es muy importante declarar las variables
compartidas.
La
compartición falsa se produce cuando dos procesos se pelean el acceso a la
misma página de memoria, ya que contiene variables que requieren los dos, pero
estas no son las mismas. Esto pasa por un mal diseño del tamaño de las páginas
y por la poca relación existente entre variables de la misma página.
En
este esquema la granularidad es más fina ya que sólo se comparten variables que
han sido marcados previamente en el código del programa.
Tanto
el compilador como el entorno de ejecución se encargan del acceso y
compartición de las variables compartidas.
4.5 Mcd en Base a Objetos
En
los MCD basados en objetos se busca el acceso a datos por medio de la
encapsulación de la información y repartida a través de la red, estos objetos
serán definidos por el Programador y las CPU cambiaran los estados según
procedan con los accesos. Nace como respuesta a la creciente popularización de
los lenguajes orientados por objetos. Los datos se organizan y son
transportados en unidades de objetos, no unidades de páginas
Una
alternativa al uso de páginas es tomar el objeto como base de la transferencia
de memoria. Aunque el control de la memoria resulta más complejo, el resultado
es al mismo tiempo modular y flexible, y la sincronización y el acceso se
pueden integrar limpiamente. Otra de las restricciones de este modelo es que
todos los accesos a los objetos compartidos han de realizarse mediante llamadas
a los métodos de los objetos, con lo que no se admiten programas no modulares y
se consideran incompatibles.
Ventajas:
·
Es
mas modular que otras técnicas.
·
La
implementación es más flexible por que los accesos son controlados.
Sincronización y accesos se pueden integrar juntos, más fácilmente
Desventajas:
·
No
corre en viejos programas para multiprocesadores.
·
Los
accesos se deben hacer invocando a los accesos, lo que significa más trabajo
que los métodos de páginas compartidas.
¿Qué son los objetos?
Estructura
de datos encapsulada definida por el programador. Se componen de datos internos
(estado) y operaciones o métodos. Cumplen con la propiedad de ocultamiento dela
información, por lo que contribuyen con la modularidad.
No
existe una memoria lineal en bruto.‡ La localización y administración de los
objetos es controlada por el sistema de tiempo de ejecución.‡ Los objetos se
pueden duplicar o no. En caso de duplicarse, hay que decidir cómo se harán las
actualizaciones.‡ Evitan el compartimiento falso.
Sus
principales desventajas son que no soportan programas multiprocesadores
antiguos y el costo adicional que genera el acceso indirecto a los datos.
Una
alternativa al uso de páginas es tomar el objeto como base de la transferencia
de memoria. Aunque el control de la memoria resulta más complejo, el resultado
es al mismo tiempo modular y flexible, y la sincronización y el acceso se
pueden integrar limpiamente. Otra de las restricciones de este modelo es que
todos los accesos a los objetos compartidos han de realizarse mediante llamadas
a los métodos de los objetos, con lo que no se admiten programas no modulares y
se consideran incompatibles.
No hay comentarios:
Publicar un comentario