Unidad 3
PROCESOS Y
PROCESADORES EN SISTEMAS DISTRIBUIDOS
3.1 Procesos, Procesadores
Conceptos
Básicos
Un hilo de ejecución, en sistemas operativos, es una
característica que permite a una aplicación realizar varias tareas
concurrentemente. Los distintos hilos de ejecución comparten una serie de
recursos tales como el espacio de memoria, los archivos abiertos, situación de
autenticación, etc. Esta técnica permite simplificar el diseño de una
aplicación que debe llevar a cabo distintas funciones simultáneamente.
Proceso
Un proceso puede
informalmente entenderse como un programa en ejecución.
Formalmente un proceso es "Una unidad de actividad que se caracteriza por
la ejecución de una secuencia de instrucciones, un estado actual, y un conjunto
de recursos del sistemas asociados"
3.2 Hilos y Multihilos
Hilos
Los hilos de ejecución que comparten los mismos recursos, sumados
a estos recursos, son en conjunto conocidos como un proceso. El hecho de que
los hilos de ejecución de un mismo proceso compartan los recursos hace que
cualquiera de estos hilos pueda modificar éstos. Cuando un hilo modifica un
dato en la memoria, los otros hilos acceden e ese dato modificado
inmediatamente.
Lo que es propio de cada hilo es el contador de programa, la pila
de ejecución y el estado de la CPU (incluyendo el valor de los registros).
El proceso sigue en ejecución mientras al menos uno de sus hilos
de ejecución siga activo. Cuando el proceso es terminado, todos sus hilos de
ejecución también lo son. Asimismo en el momento en el que todos los hilos de
ejecución finalizan, el proceso no existe más y todos sus recursos son
liberados.
Un ejemplo de la utilización de hilos es tener un hilo atento a la
interfaz gráfica (iconos, botones, ventanas), mientras otro hilo hace una larga
operación internamente. De esta manera el programa responde de manera más ágil
a la interacción con el usuario. También pueden ser utilizados por una
aplicación servidora para dar servicio a múltiples clientes.
Multihilo
Sincronización de hilos
Todos los hilos comparten el mismo espacio de direcciones y otros
recursos como pueden ser archivos abiertos. Cualquier modificación de un
recurso desde un hilo afecta al entorno del resto de los hilos del mismo
proceso. Por lo tanto, es necesario sincronizar la actividad de los distintos
hilos para que no interfieran unos con otros o corrompan estructuras de datos.
Una ventaja de la programación multihilo es que los programas
operan con mayor velocidad en sistemas de computadores con múltiples CPU
(sistemas multiprocesador o a través de grupo de máquinas) ya que los hilos del
programa se prestan verdaderamente para la ejecución concurrente.
Formas de Multihilos
Los sistemas operativos generalmente implementan hilos de dos
maneras:
Multihilo
apropiativo
Permite al sistema operativo determinar cuándo debe haber un
cambio de contexto. La desventaja de esto es que el sistema puede hacer un
cambio de contexto en un momento inadecuado, causando un fenómeno conocido como
inversión de prioridades y otros problemas.
Multihilo
cooperativo
Depende del mismo hilo abandonar el control cuando llega a un
punto de detención, lo cual puede traer problemas cuando el hilo espera la
disponibilidad de un recurso.
El soporte de Hardware para multihilo desde hace poco se encuentra
disponible.
3.3 Modelos de
Procesadores
EVOLUCION DE LOS
PROCESADORES
Hablar de procesadores es, sobre todo, hablar de
Intel y de AMD, ya que son las empresas que han soportado el peso del
desarrollo de estos, ya sea colaborando ambas empresas como en su fase de
desarrollos independientes.
Aunque la historia de los ordenadores comienza
bastante antes, la historia de los microprocesadores comienza en el año 1971,
con el desarrollo por parte de Intel del procesador 4004, para facilitar el
diseño de una calculadora.
Al mismo tiempo, la empresa Texas Instruments
(conocida por el diseño y fabricación de calculadoras) también trabajaba en un
proyecto similar, por lo que aun se discute quien fue el creador del primer
microprocesador, si Texas Instruments o Intel. Vamos a limitar a la época de los PC
(Personal Computer), que podemos decir que comienza en el año 1978, con la
salida al mercado del procesador Intel
8086.
Hablando de la historia de los ordenadores
personales y sus procesadores no podemos olvidar a Apple y su Macintosh, ni a
Motorola y su Power PC, pero en este tutorial nos vamos a centrar en los
procesadores que utilizan los juegos de instrucciones x86 y x64 (los actuales procesadores de 64
bits).
8086 y
8088 (1978 a 1982)
Son los primeros procesadores utilizados en PC.
La diferencia entre los 8086 y los 8088 estaba
en su frecuencia, que en el caso del 8086 era de unos ''sorprendentes''
4.77Mhz, pasando en los 8088 a una frecuencia de entre 8 y 10Mhz, pudiendo
gestionar 1Mb de memoria.
Usaban un socket de 40 pines (paralelos 20 + 20)
y tenían un bus externo de entre 8 y 16 bits.
Carecían de instrucciones de coma flotante, pero
para implementar estas se podían complementar con el coprocesador matemático
8087, que era el más utilizado, aunque no el único, ni tan siquiera el que
ofrecía un mejor rendimiento.
De los dos modelos, el más utilizado sin duda
fue el 8088, que además fue el utilizado por IBM en su IBM PC.
El modelo 8086 aun es utilizado en algunos
dispositivos y calculadoras.
80186 y 80188 (1982 hasta nuestros días)
Se trata de una evolución de los modelos 8086 y 8088.
Si bien su uso como procesadores para ordenador
tuvo muy poco uso e incidencia, siendo utilizado como tal por tan solo un par
de fabricantes de PC, no se puede decir lo mismo sobre su importancia, ya que
se siguen utilizando en nuestros días (en su versión CMOS), sobre todo por su
capacidad de desarrollar las funciones que de otra forma tendrían que estar
distribuidas entre varios circuitos.
En lugar de socket utilizaban una presentación
tipo chip (la misma que utilizan hoy como CMOS), con una frecuencia de 6Mhz.
80286 (1982 a 1986)
Más conocido como i286 o simplemente como 286, se trata de un
procesador en el que ya aparece la forma definitiva que llega hasta hoy
(cuadrado, con los pines en una de sus caras), insertado en un socket de 68
pines, si bien también hubo versiones en formato chip de 68 contactos.
Los primeros 80286 tenían una frecuencia de 6 y
8Mhz, llegando con el paso del tiempo a los 25Mhz.
Funcionaban al doble de velocidad por ciclo de
reloj que los 8086 y podían direccionar 16Mb de memoria RAM.
Los 80286 fueron desarrollados para poder
trabajar en control de procesos en tiempo real y sistemas multiusuario, para lo
que se le añadió un modo protegido. En este modo trabajaban las versiones de 16
bits del sistema operativo OS/2. En este modo protegido se permitía el uso de
toda la memoria directamente, ofreciéndose además una protección entre
aplicaciones para evitar la escritura de datos accidental fuera de la zona de
memoria asignada (un sistema en buena parte similar al actual Bit de
desactivación de ejecución de datos en su funcionamiento).
Los procesadores 80286 fueron fabricados bajo
licencia de Intel por varios fabricantes además de la propia Intel, como AMD,
Siemens, Fujitsu y otros.
80386 (1986 hasta 1994)
La aparición en el año 1986 de los procesadores
80386 (más conocido como i386)
supuso el mayor avance hasta el momento en el desarrollo de los procesadores,
no solo por lo que supusieron de mejora sobre los 80286 en cuanto a
rendimiento, sino porque es precisamente con este procesador con el que se
sientan las bases de la informática tal como la conocemos.
Esto llega hasta el punto de que si no fuera por
el rendimiento y frecuencias, cualquier programa actual podría funcionar
perfectamente en un 80386 (cosa que no ocurre con los procesadores anteriores).
Se trata del primer procesador para PC con una
arquitectura CISC de 32bits e instrucciones x86 de direccionamiento plano
(IA32), que básicamente es la misma que se utiliza en nuestros días.
Al tratarse de procesadores de 32bits podían
manejar (en teoría) hasta 4Gb de RAM.
Fueron también los primeros procesadores a los
que se adaptó un disipador para su refrigeración.
Aclaro lo de ''para PC'' porque Motorola, con su
Motorola 68000 para Mac hacia tiempo que ya utilizaba el direccionamiento
plano.
La conexión a la placa base en las primeras
versiones es mediante socket de 68 pines, igual al de los 80286 pero no
compatibles, por lo que también significó el desarrollo de placas base
específicas para este procesador, pasando posteriormente a un socket de 132
pines.
Con unas frecuencias de entre 16 y 40Mhz, se
fabricaron en varias versiones.
80386 - A la que nos hemos referido hasta el momento.
i386SX - Diseñado como versión económica del 80386. Seguía
siendo un procesador de 32bits, pero externamente se comunicaba a 16bits, lo
que hacía que fuera a la mitad de la velocidad de un 80386 normal.
i386SX Now - Versión del 80386SX, pero con el patillaje
compatible pin a pin con los procesadores 80286, desarrollado por Intel para poder
actualizar los 80286 sin necesidad de cambiar de placa base.
i386DX - Es la denominación que se le dio a los 80386 para
distinguirlos de los 80386SX cuando estos salieron al mercado.
Este procesador supuso la ruptura de la
colaboración de Intel con otros fabricantes de procesadores, lo que tuvo como
consecuencia que la gran mayoría de ellos dejaran de fabricar estos.
La gran excepción fue AMD, que en 1991 sacó al
mercado su procesador Am386,
totalmente compatible con los i386, lo que terminó con el monopolio de Intel en
la fabricación de estos.
Aunque no se utilizan en ordenadores, este
procesador sigue en producción por parte de Intel, habiendo anuncio el fin de
esta para mediados de 2007.
80486 (1989 a 1995)
Más conocidos como i486, es muy similar al i386DX,
aunque con notables diferencias.
De este tipo de procesador ha habido muchas
versiones, tanto de Intel como de otros fabricantes a los que les fue
licenciado.
En ocasiones se trataba de procesadores iguales
a los de Intel y en otras de diseños propios, como fue el caso de los Am486 de
AMD.
Las frecuencias de estos procesadores fueron
creciendo con el tiempo, llegando al final de su periodo de venta a los 133Mhz
(en el caso del Am486 DX5 133), lo que lo convirtió en uno de los procesadores
más rápidos de su época (y hay que tener en cuenta que los Pentium ya estaban en el mercado).
Las más frecuentes fueron 25Mhz, 33Mhz, 40Mhz,
50Mhz (con duplicación del reloj), 66Mhz (con duplicación del reloj), 75Mhz
(con triplicación del reloj), 100Mhz (con triplicación del reloj) y en el caso
de AMD (en los Am486DX5) 120Mhz y 133Mhz.
En un primer momento también salieron con unas
frecuencias de 16Mhz y de 20Mhz, pero estas versiones son muy raras.
Con respecto a los Am486DX5 133 (también conocidos como Am5x86 133), hay que señalar
que se trataba del procesador de mayor rendimiento de su época.
Las novedades en estos procesadores i486 fueron
muchas, como por ejemplo un conjunto de instrucciones muy optimizado, unidad de
coma flotante integrada en el micro (fueron los primeros en no necesitar el
coprocesador matemático), una caché integrada en el propio procesador y una
interface de bus mejorada. Esto hacia que a igualdad de frecuencia que un i386
los i486 fueran al doble de velocidad.
En cuanto a las versiones de los i486, podemos destacar:
Intel 80486-DX - La versión modelo, con las características indicadas
anteriormente.
Intel 80486-SX - Un i486DX con la unidad de coma flotante
deshabilitada, para reducir su coste.
Intel 80486-DX2 - Un i486DX que internamente funciona al doble de la
velocidad del reloj externo.
Intel 80486-SX2 - Un i486SX que funciona internamente al doble de la
velocidad del reloj.
Intel 80486-SL - Un i486DX con una unidad de ahorro de energía.
Intel 80486-SL-NM - Un i486SX con una unidad de ahorro de energía.
Intel 80486-DX4 - Un i486DX2 pero triplicando la velocidad interna.
Intel 80486 OverDrive (486SX, 486SX2, 486DX2
o 486DX4) - variantes de los
modelos anteriores, diseñados como procesadores de actualización, que tienen un
patillaje o voltaje diferente. Normalmente estaban diseñados para ser empleados
en placas base que no soportaban el microprocesador equivalente de forma
directa.
Pentium (1993 a 1997)
Este procesador fue creado para sustituir al i486
en los PC de alto rendimiento, si bien compartió mercado con ellos hasta el año
1.995, siendo precisamente estos su gran rival, ya que tuvieron que pasar
algunos años (y versiones del Pentium) para que superara a los i486 DX4 en
prestaciones, siendo además mucho más caros.
Los primeros Pentium tenían una frecuencia de
entre 60Mhz, 66Mhz, 75Mhz y 133Mhz, y a pesar de las mejoras en su estructura,
entre las que destaca su arquitectura escalable, no llegaban a superar a los
i486 de Intel que en ese momento había en el mercado, y mucho menos a los Cyrix
y Am486 DX4.
En enero de 1997 salió al mercado una evolución
de los Pentium llamada Pentium
MMX (Multimedia Extensions),
al añadírsele a los Pentium un juego de instrucciones multimedia que agilizaba
enormemente el desarrollo de estos, con unas frecuencias de entre 166Mhz y
200Mhz.
Los Intel Pentium MMX utilizaban los socket 7,
de 321 pines y entre 2.5 y 5v. Estos socket son los que también utilizaban los
procesadores de la competencia de Intel, tanto los AMD K5 y K6 como los Cyrix
6x86.
Los primeros K5 aparecieron en 1996. Se trataba
de unos procesadores basados en la arquitectura RISC86, más próximos a lo que
después serían los Pentium PRO y con un nivel de prestaciones desde un principio
muy superior a los Pentium de Intel, pero con una serie de problemas, más de
fabricación que del propio procesador, que hicieron que los K5 fueran un
fracaso para AMD, y si bien los problemas se solucionaron totalmente con la
salida de los K6, Intel supo aprovechar muy bien esta circunstancia para
imponerse en el mercado de los procesadores para PC.
Utilizaban para las funciones multimedia las
instrucciones MMX, que se habían convertido en el estándar de la época.
En 1997 salen al mercado los AMD K6.
Diseñados para trabajar en placas base de Pentium
dotadas de socket 7 y con unas frecuencia de entre 166 y 300Mhz, tuvieron una
pronta aceptación en el mercado, ya que no solo tenían un precio bastante
inferior a los Pentium MMX de Intel, sino también unas prestaciones muy
superiores a estos y a los Cyrix 6x86, que se quedaron bastante descolgados.
Pentium Pro (1995 hasta 1998)
El Pentium
PRO no fue diseñado como
sustituto de ningún procesador, sino como un procesador para ordenadores de
altas prestaciones destinados a estaciones de trabajo y servidores.
Basado en el nuevo núcleo P6, que más tarde seria
adoptado por los Pentium II y Pentium III, utilizaba el socket 8, de forma
rectangular y 387 pines, desarrollado exclusivamente para este procesador.
Con una frecuencia de reloj de 133 y 200Mhz,
incorpora por primera vez un sistema de memoria caché integrada en el mismo
encapsulado. Esta cache podía ser de 256Kb, 512Kb o de 1Mb.
Sobresalían en el manejo de instrucciones y
software de 32 bits, en máquinas trabajando bajo Windows NT o Unix, pero casi
siempre resultaban más lentos que un Pentium (y no digamos que un AMD K6) en
programas e instrucciones de 16 bits.
Estos procesadores no llegaron nunca a
incorporar instrucciones MMX.
Pentium II (comienzos de 1997 a mediados de 1999)
A comienzo de 1.997 Intel saca al mercado a bombo
y platillo, y con una campaña de propaganda nunca antes vista para el
lanzamiento de un procesador, el Pentium
II.
Se trata de un procesador basado en la arquitectura
x86, con el núcleo P6, que
fue utilizado por primera vez en los Pentium
Pro.
Con el lanzamiento de este procesador se produce
la separación definitiva entre Intel y AMD... y llega la incompatibilidad de
placas base entre ambos.
También se produce por parte de Intel el
abandono de los socket, en favor de instalar los procesadores enSlot, en
este caso Slot 1, de 242
contactos y de entre 1.3 y 3.3 voltios, que por cierto, sería abandonado
posteriormente ante los problemas que este sistema genera.
Estos procesadores, que como ya hemos dicho
estaban basados más en los Pentium Pro que en los Pentium originales, contaban
con memoria caché, tanto de nivel L1 (32Kb) como de nivel L2 (512Kb), pero a
diferencia de lo que ocurría en los Pentium Pro no estaba integrada en el
encapsulado del procesador, sino unida a este por medio de un circuito impreso.
Para complicar más el tema, se les dota de instrucciones MMXy se les mejora el
rendimiento en ejecuciones de 16bits.
Klamath
A la venta desde mayo de 1.997, con un FSB de 66Mhz y
frecuencias de 233Mhz, 266Mhz y 300Mhz.
Sustituye a la serie Klamath en enero de 1.998.
Se comercializa con dos frecuencias de FSB
diferentes y con velocidades de entre 266Mhz y 450Mhz.
- FSB 66Mhz - 266Mhz, 300Mhz y 333Mhz.
- FSB 100Mhz - 350Mhz. 400Mhz y 450Mhz.
También, y en un intento por dominar totalmente
el mercado cubriendo el espectro de ordenadores más económicos, Intel introduce
en 1.998 la gama Celeron.
En agosto de 1998 Intel saca al mercado una
nueva gama de procesadores económicos, denominados Intel Celeron, denominación que
llega hasta nuestros días.
La principal finalidad de esta gama fue y es la
de ofrecer procesadores al bajo precio para frenar el avance de AMD.
En esta fecha, Intel lanza el primer Celeron,
denominado Covington.
Este procesador no era otra cosa que un Pentiun
II a 266 o a 300Mhz, pero sin memoria Caché L2.
Tenían una velocidad superior a los MMX, pero su
rendimiento efectivo era bastante pobre, por lo que después de un éxito inicial
(basado sobre todo en la fuerza de la marca, más que en las cualidades del
producto), Intel se planteó su sustitución.
Por su parte, AMD no respondió a la salida de los Intel
Pentium II hasta mayo de 1.998, con la salida al mercado del nuevo AMD K6-2.
Este procesador siguió utilizando el socket 7 en
las versiones de hasta 550Mhz y el socket Súper7, que permitía el uso de AGP.
En general, los Mendocinos eran más rápidos en
accesos a caché y tenían un excelente rendimiento en operaciones de coma
flotante frente a los K6-2, pero estos tenían una mayor velocidad de acceso a
memoria y un mejor desempeño multimedia, debido sobre todo a la utilización de
un FSB a 100Mhz y al conjunto de instrucciones 3DNow!, que con las debidas
actualizaciones y mejoras sigue utilizando AMD en la actualidad.
La gama de AMD K6-2 iba desde los 233Mhz hasta
los 550Mhz, con una caché L1 de 64Kb (32 para instrucciones y 32 para datos, en
acceso exclusivo).
Este procesador, de un gran éxito comercial,
afianzó las bases de AMD y permitió el posterior desarrollo de los AMD Athlon.
Pentium
III (1999 hasta 2003)
En febrero de 1999 Intel lanza el sustituto del
Pentium II, el Pentium III.
Entre 1999 y 2003 se produjeron Pentium III en
tres modelos diferentes:
Katmai: De diseño muy similar al Pentium II, introduce el juego
de instrucciones SSE, que ya no implica la deshabilitación de la unidad de coma
flotante para poder realizar las funciones multimedia, tal como ocurría con
MMX, así como un controlador mejorado de caché.
El Pentium III Katmai utilizaba el mismo Slot 1 que los
Pentium II, pero se fabricaron con unos FSB de 100Mhz y de 133Mhz.
En un principio sus frecuencias eran de 450Mhz y
500Mhz, y en mayo de 1.999 salieron al mercado los Katmai de 550Mhz y 600Mhz.
Coppermine:A finales de 1.999 sale al mercado la versión Coppermine.
Esta versión incluye un aumento de caché L2 hasta
los 256Kb.
Esta serie utiliza tanto el Slot 1 como el nuevo
Socket 370, introducido en el mercado para estos procesadores.
Incluso existía un adaptador para poder utilizar
los Coppermone 370 en slot 1.
Se fabricaron con unas velocidades de 500Khz,
533Mhz, 550Mhz, 600Mhz, 650Mhz, 667Mhz, 700Mhz y 733Mhz.
En el año 2.000 salieron las versiones de 750Mhz,
800Mhz, 850Mhz, 866Mhz, 933Mhz y 1Ghz.
Esta versión no ha muerto, ya que los primeras
consolas Xbox lo utilizan en una versión especial de 900Mhz.
Tualatin: Introducida en el año 2.001, se trata de la última
serie de Pentium III, ya desarrollada solo para socket 370, con unas
velocidades de 1.13Ghz, 1.2Ghz, 1.26Ghz y 1.4Ghz y un FSB de 133Mhz.
Estos procesadores contaban con 256Kb de caché, y
en la versión Pentium III-S (versión para servidores), con 512Kb.
Durante este periodo, Intel también potenció la
Gama Celeron, con una
serie de mejoras introducidas en este, así como una serie de modelos
diferentes:
Celeron Coppermine-128: En Marzo de 2000, Intel pone finalmente a la venta los
nuevos Celeron Coppermine-128,
conocidos también como Celeron
II.
Estos procesadores estaban basados en los Pentium
III Coppermine, pero con un FSB de 66Mhz y tan solo 128Kb de caché.
Estos Celeron no destacaban precisamente por su
rendimiento, que no supuso una gran mejora sobre el Mendocino.
Se fabricaron en velocidades que iban desde los
533Mhz a los 766Mhz.
Celeron Tuatalin: En 2002 se introducen los Celeron Tuatalin, basados en
los Pentium III del mismo nombre, a los que se les había reducido el FSB a
100Mhz, con la misma caché que los Pentium III, es decir, 256Kb.
Las primeras versiones de este nuevo Celeron
tenían una velocidades de 1Ghz y 1.1Ghz, y se les denomina como Celeron A para diferenciarlos de los Celeron
Coppermine de esas velocidades.
Posteriormente se sacaron al mercado versiones de
1.2Ghz, 1.3Ghz y 1.4Ghz.
Athlon Classic: Aunque basado en parte en el K6-2, se le mejora
notablemente el rendimiento de coma flotante al incorporar 3 unidades que
pueden funcionar simultáneamente, incorporando también las instrucciones 3DNow!. También se eleva la
caché L1 a 128Kb (64 para instrucciones y 64 para datos) y se le incorporan
512Kb de caché L2, montados externamente (al igual que los P-II y los P-III de
slot 1).
Pero quizás la mayor diferencia la marca la
utilización del FSB compatible con el protocolo EV6 de Alpha.
Este bus funciona en esta versión a 100Mhz DDR (Dual Data Rate), lo que
lo convierte en 200Mhz efectivos.
AMD Duron: La primera serie de AMD
Duron, denominada Spitfire,
sale al mercado a mediados de 2.000 para competir en el mercado de los
procesadores económicos con los Intel Celeron, batiendo a estos en prestaciones
desde el primer momento.
Esta primera serie no es otra cosa que un Athlon
Thunderbird al que se le ha reducido la caché L2 a 64Kb, en lugar de los 256Kb
de los Athlon, pero manteniendo el resto de especificaciones, incluido el FSB
EV6 de 100Mhz DDR (200Mhz efectivos).
Tenían en esta versión una frecuencia de entre
600Mhz y 1.2Mhz, un extraordinario rendimiento en operaciones de coma flotante
y contaban con las instrucciones 3DNow!.
En noviembre del año 2.000 Intel saca al mercado
el procesador Intel Pentium 4,
que estuvieron durante unos años compartiendo mercado con los Pentium III y AMD
Athlon y Athlon XP.
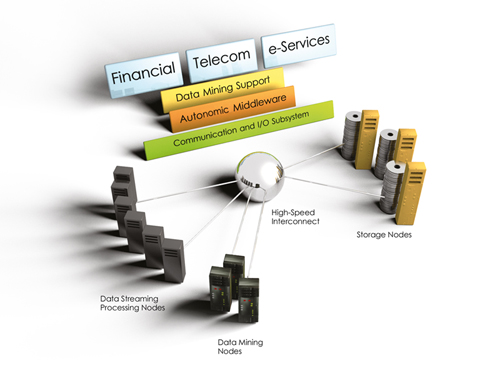
El sistema consta de estaciones de
trabajo (PC) dispersas conectadas entre sí mediante una red de área local
(LAN).
Los usuarios tienen:
· Una
cantidad fija de poder de cómputo exclusiva.
· Un
alto grado de autonomía para asignar los recursos de su estación de trabajo.
Uso de los discos en las estaciones de
trabajo:
Sin disco:
· Bajo
costo, fácil mantenimiento del hardware y del software, simetría y
flexibilidad.
· Gran
uso de la red, los servidores de archivos se pueden convertir en cuellos de
botella.
Disco para paginación y archivos de tipo borrador:
· Reduce
la carga de la red respecto del caso anterior.
· Alto
costo debido al gran número de discos necesarios.
Disco para paginación, archivos de tipo borrador y
archivos binarios (ejecutables):
· Reduce
aún más la carga sobre la red.
· Alto
costo y complejidad adicional para actualizar los binarios.
Disco para paginación, borrador, binarios y
ocultamiento de archivos:
· Reduce
aún más la carga de red y de los servidores de archivos.
· Alto
costo.
· Problemas
de consistencia del caché.
Sistema local de archivos completo:
· Escasa
carga en la red.
· Elimina
la necesidad de los servidores de archivos.
· Pérdida
de transparencia.
Se dispone de un conjunto de CPU que se
pueden asignar dinámicamente a los usuarios según la demanda.
Los usuarios no disponen de estaciones
de trabajo sino de terminales gráficas de alto rendimiento.
No existe el concepto de propiedad de
los procesadores, los que pertenecen a todos y se utilizan compartidamente.
El modelo de pila es más eficiente que
el modelo de búsqueda de estaciones inactivas.
También existe el modelo híbrido que
consta de estaciones de trabajo y una pila de procesadores.
- Los trabajos interactivos se ejecutan
en las estaciones de trabajo mientras que los no interactivos se ejecutan en la
pila de procesadores.
- El
Modelo de las Estaciones de trabajo suele coincidir en la actualidad con la
mayoría de las organizaciones.
- Cuando
se utiliza este modelo hay una serie de aspectos a tener en cuenta:
• La asignación de Procesos a los
Procesadores.
• Los Algoritmos de Distribución de la
Carga.
• La Planificación de los Procesos en
un Sistema Distribuido.
Son necesarios algoritmos para decidir
cuál proceso hay que ejecutar y en qué máquina.
Para el modelo de estaciones de
trabajo:
·
Decidir cuándo ejecutar el proceso de
manera local y cuándo es necesario buscar estaciones inactivas o no locales que
tienen una conexión a la misma red pero fuera de ella.
Para el modelo de la pila de
procesadores:
·
Decidir dónde ejecutar cada nuevo
proceso respecto de la misma maquina que es la tabla(lista) de los procesos que
se crean dentro de la maquina.
Aspectos del Diseño de
Algoritmos de Asignación de Procesadores
Los principales aspectos son los
siguientes:
Algoritmos deterministas vs.
heurísticos.
Los algoritmos deterministas son
adecuados cuando se sabe anticipadamente todo acerca del comportamiento de los
procesos, pero esto generalmente no se da, aunque puede haber en ciertos casos
aproximaciones estadísticas. Los algoritmos heurísticos son adecuados cuando la
carga es impredecible.
Algoritmos centralizados vs.
distribuidos.
Los diseños centralizados permiten
reunir toda la información en un lugar y tomar una mejor decisión; la
desventaja es que la máquina central se puede sobrecargar y se pierde robustez
ante su posible falla.
Algoritmos óptimos vs. subóptimos.
Generalmente los algoritmos óptimos
consumen más recursos que los subóptimos, además, en la mayoría de los sistemas
reales se buscan soluciones subóptimas, heurísticas y distribuidas.
Algoritmos locales vs. globales.
Los algoritmos locales son sencillos
pero no óptimos.
Los algoritmos globales son mejores
pero consumen muchos recursos.
Algoritmos iniciados por el emisor vs.
iniciados por el receptor.
Casi todos los algoritmos suponen que
las máquinas conocen su propia carga y que pueden informar su estado:
- La
medición de la carga no es tan sencilla.
- Un
método consiste en contar el número de procesos (hay que considerar los
procesos latentes no activos). Otro método consiste en contar solo los procesos
en ejecución o listos.
- También
se puede medir la fracción de tiempo que la CPU está ocupada.
- Otro
aspecto importante es el costo excesivo en consumo de recursos para recolectar
medidas y desplazar procesos, ya que se debería considerar el tiempo de CPU, el
uso de memoria y el ancho de banda de la red utilizada por el algoritmo para
asignación de procesadores.
- Se
debe considerar la complejidad del software en cuestión y sus implicancias para
el desempeño.
- Si
el uso de un algoritmo sencillo proporciona casi la misma ganancia que uno más
caro y más complejo, generalmente será mejor utilizar el más sencillo.
Se debe otorgar gran importancia a la
estabilidad del sistema:
- Las
máquinas ejecutan sus algoritmos en forma asíncrona por lo que el sistema nunca
se equilibra.
La mayoría de los algoritmos que
intercambian información:
- Son
correctos luego de intercambiar la información y de que todo se ha registrado.
- Son
poco confiables mientras las tablas continúan su actualización, es decir que se
presentan situaciones de no equilibrio.
· Toma
en cuenta los patrones de comunicación entre los procesos durante la
planificación.
· Debe
garantizar que todos los miembros del grupo se ejecuten al mismo tiempo.
· Se
emplea una matriz conceptual donde:
· Las
filas son espacios de tiempo.
· Las
columnas son las tablas de procesos de los procesadores.
· Cada
procesador debe utilizar un algoritmo de planificación round robin:
· Todos
los procesadores ejecutan el proceso en el espacio “0” durante un cierto
periodo fijo.
· Todos
los procesadores ejecutan el proceso en el espacio “1” durante un cierto
periodo fijo, etc.
· Se
deben mantener sincronizados los intervalos de tiempo.
· Todos
los miembros de un grupo se deben colocar en la misma n°
de espacio de tiempo pero en procesadores distintos.
La capacidad de procesamiento está
distribuida entre varios computadores interconectados.
- Las actividades del sistema tienen requisitos
de tiempo.
- Necesidad de sistemas distribuidos:
/Requisitos de procesamiento.
/Distribución física del sistema.
/Fiabilidad: Tolerancia a fallos.
- Los sistemas distribuidos de tiempo real
(SDTR) son complicados de realizar.
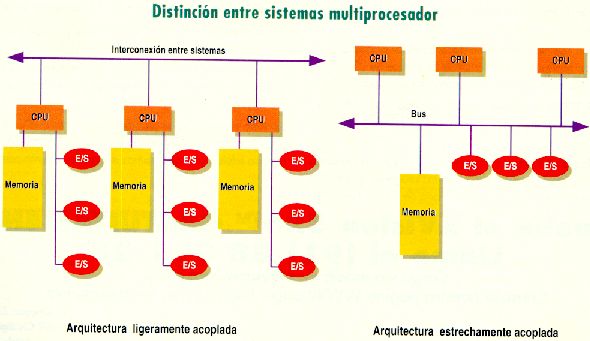
- Se consideran sistemas débilmente acoplados.
- Comunicación mediante mensajes
- El tiempo de comunicación es significativo.
- Ej. Sistemas multimedia, SCADA, aviónica,
fabricación integrada, robótica.
- Distintos tipos de requisitos temporales
- Se consideran, fundamentalmente, sistemas
críticos

























.JPG/76081351/553x303/fig_(7).JPG)